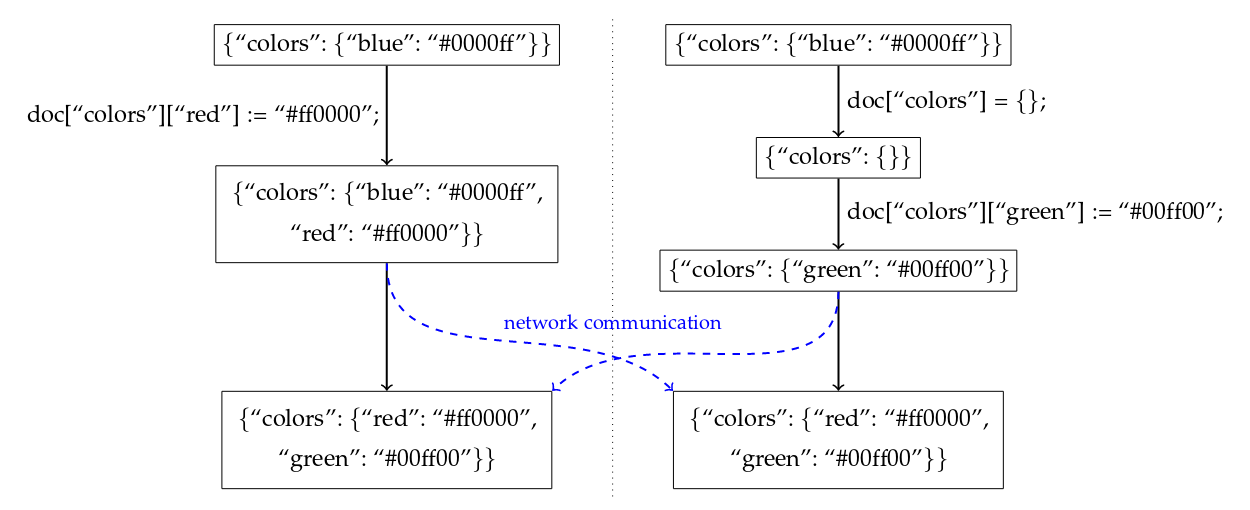
The abstract does make pretty strong claims, but note that JSON doesn’t describe the full semantics of the contained data. The presented algorithm can only guarantee that valid JSON comes out, but possibly not in the format expected by the application.
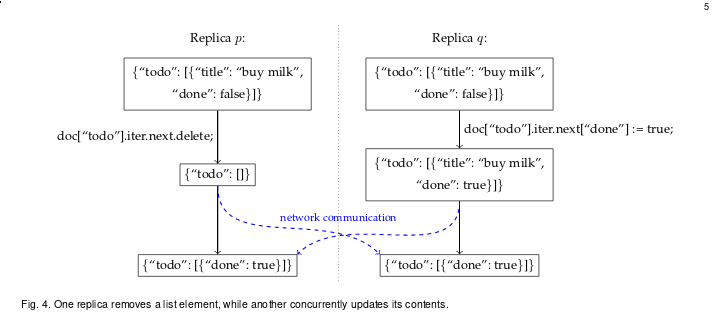
An example is given on page 5:
The algorithm doesn’t understand that a task is only valid if it has both a "title" and a "done" field. When a task is deleted, it instead interprets this similar to “two keys got deleted”. When “done” is set to true, it is reinserted, creating a bogus task item.
Of course you could then add a post-processing step which then discards invalid items, but do you really want that? Task items may get corrupted for entirely different reasons, and silently discarding them is the worst way to deal with them, even if there’s not much to recover from {"done": true}. Practically, this is not actually a “conflict-free” sync algorithm. It only limits you to one single conflict resolution (discarding), and you still have to add application-specific code for that.
Ideas for remoteStorage.js
IMO in practice you don’t really get around implementing an application-specific UI for when conflicts happen, if storing both versions of the conflicting data (like Dropbox does) is not an option. Unfortunately remoteStorage.js leaves this largely to the developer.
remoteStorage.js could offer a full ORM
It also allows remoteStorage.js to store the data in a proper database (no idea what options there are on the client side), and only (de-)serialize data when down-/uploading. Having a database means that you can automatically index your data, another burden taken off the application developer’s back.
remoteStorage.js can currently maximally know three things when synchronizing:
- the file’s state on side A
- the file’s state on side B
- the file’s state after the last sync (which was equal on A and B back then)
It can merely choose one of those states, and has no idea how to merge them. But with an ORM, remoteStorage.js can at least do this sort of conflict resolution per-field.
At this point we’re basically reinventing databases. I think http://hood.ie is miles ahead of remoteStorage.js in that regard, but there’s not that much you can do with a simple filesystem/kv-store.
When syncing, remoteStorage.js would automatically serialize to JSON. This means that the data on the user storage is not compatible with any existing standard (just raw JSON instead of e.g. iCalendar files), in exchange for making applications with complex data schemas much easier to write.
But even that one disadvantage can be removed by allowing the application developer to define their own serialization and deserialization functions. A calendar app would by default create one JSON file per event in its own proprietary JSON-schema autogenerated by remoteStorage.js, but the developer could still go the extra mile and override this behavior with their own application-specific logic.
remoteStorage.js could implement its own conflict resolution prompt
Since remoteStorage.js now knows so much about the data it stores, it can now show a simple dialog that shows the conflicting task items side by side and ask the user to pick one. This doesn’t necessarily look pretty since it will also show a lot of internal information (such as the table row’s ID).
At this point it might also make sense to integrate with UI frameworks such that the application developer can pass e.g. a React component that takes a task and represents it nicely when attached to the DOM.
 Domain knowledge helps a lot with conflict resolution (I think this is what you mean with ‘a full ORM’).
Domain knowledge helps a lot with conflict resolution (I think this is what you mean with ‘a full ORM’).