In order to make the brainstorming of potential routes a bit easier, here is an example of how I’m using remoteStorage without currently having any shared data model or rs.js module for it:
Public profile information
I’m storing some public profile information in my storage, which (as of now) I am the only producer and consumer of. However, I actually intended this as something that could be retrieved from other people’s storages as well in the future.
Use case: As a frequent traveler, I want other people to know where I currently am, and also in which timezone. To render it nicely on my personal website, I also want people to see a map with a rough location. So I use this simple app (source code) I wrote in order to upload two documents to my /public/profile:
Here’s the current content of the current-location:
{
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [
12.127262,
47.8539273
]
},
"city": "Rosenheim",
"state": "Bavaria",
"country": "Germany",
"timezone": {
"name": "Europe/Berlin",
"now_in_dst": 1,
"offset_sec": 7200,
"offset_string": "+0200",
"short_name": "CEST"
}
}
As you can see, I didn’t need to invent my own format for the location from scratch, as GeoJSON already standardizes how to describe a geographic location. However, that’s only true for the location data itself, not including e.g. city/state/etc. names or timezone information. (The GeoJSON spec allows using arbitrary custom properties in addition to the standardized ones.)
The PNG file contains the rendered map I mentioned. Currently, it looks like this:
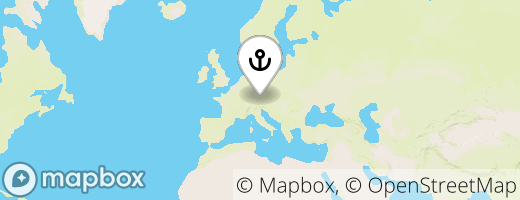
Both the city name and map image are then rendered by a few lines of vanilla JS on my personal website. But obviously, it could be useful in a lot of different scenarios and more complex applications.
Questions
Now, these things would still easily fit in a current rs.js data module, which would have a few functions to store and retrieve the location and timezone data. I could extract some things from the rs-locate code, and maybe the module would even allow you to use OpenCage (geocoding) and Mapbox (map rendering) API keys with it, so it could do everything that the app currently does.
However, this raises some questions:
- How could the module “import”/extend the GeoJSON format and schema instead of redefining everything in our own schema?
- Should the schema actually be specified in the module code, meaning an “extended location object” (or whatever the name/
@type would be) cannot be shared across modules?
- Should the
/profile/current-location (and current-location.png) naming scheme be hardcoded in a rs.js module only? In essence, these are well-known URIs, same as the /.well-known/ ones that are specified over at IANA for example (but only for RS storage base URLs in our case).
- How would I go about proposing this for standardization (simply meaning: please, nobody else use these URIs for other things in their RS apps, and please do it the same way, if it solves a use case in your app)? How much peer review do we want to consider something standard? How would we discern between “standardized” and “custom” data?
- If any of this would be published separate from rs.js module code, then where and how? And how could it be used in either rs.js directly, or from rs.js modules?
- What about specifying details that don’t seem important, but can make or break UX in apps? E.g. the aspect ratio and resolution of the map image.
I realize the map image is a bit of a special case, but we actually already have a similar issue in the shares module (used in Sharesome e.g.), with the thumbnails it uses for previews.
The naming (or at least structure/ontology) for paths and documents, on the other hand, is something we need for virtually all data models/modules. Same for re-using, and linking and/or extending existing schemas I suppose.
These are a lot of questions, but anyway, I hope this creates a basis for some brainstorming.  Let’s just throw around some ideas for potential answers to these questions, and maybe we can see some shapes forming.
Let’s just throw around some ideas for potential answers to these questions, and maybe we can see some shapes forming.