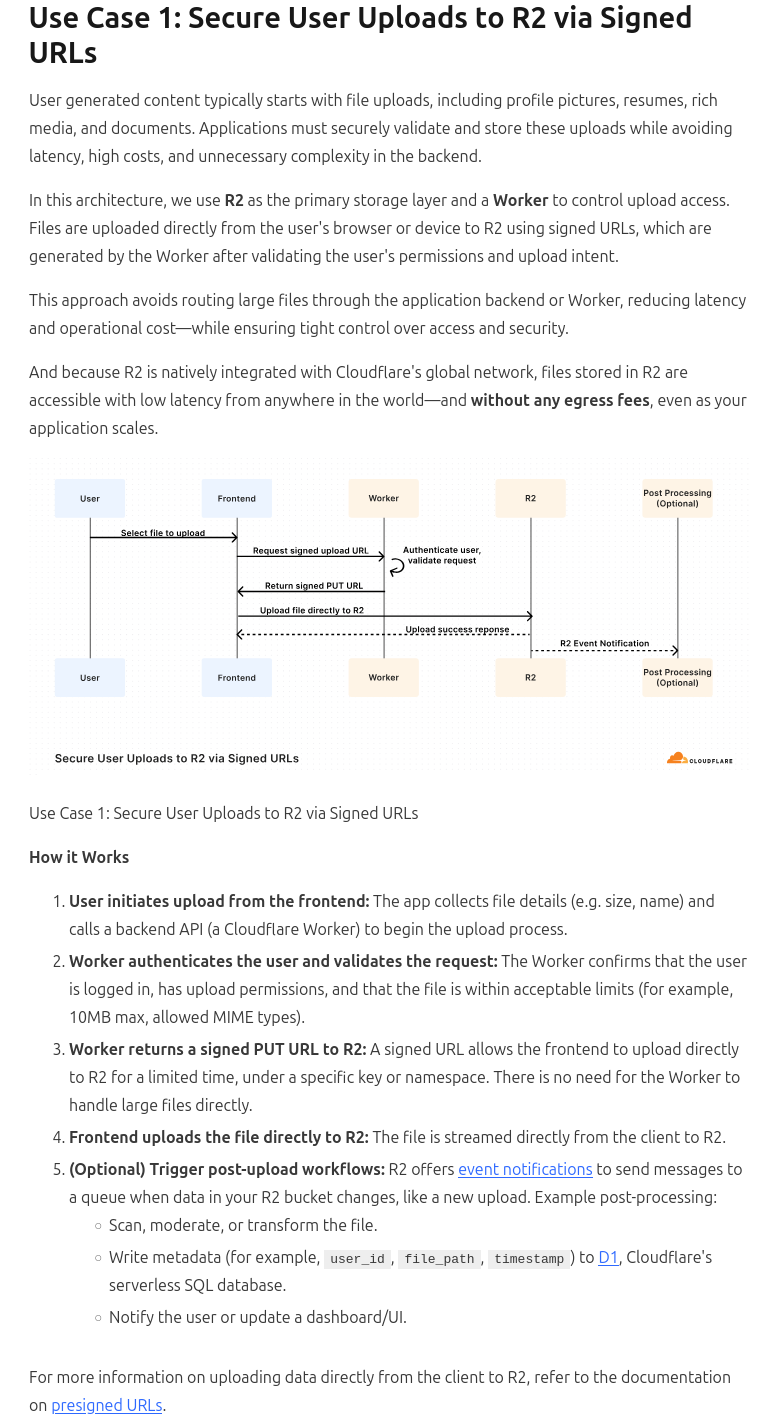
To make it easier for application authors to migrate to remoteStorage (and make it easier to author an extension that intercedes on app-to-cloud-bucket calls to read, write, and/or copy to a remoteStorage account of the user’s choice), the/a remoteStorage library should offer an S3 compatibility layer.
(That is: all on the client—not an extension of the HTTP APIs that a conformant remoteStorage server should implement. It should also be possible to ask remoteStorage.js (or whatever library implementing this) to provide a custom fetch and/or XMLHttpRequest implementation to overwrite the browser’s native fetch/xhr.)
How would it be possible to handle per-user auth purely on the client side? I don’t see any option that doesn’t require running a server program for that.
Can you be more specific (scenario/user story)? This would be where an existing site has existing infrastructure in place to put and fetch data on the server at the operator’s expense rather than the accountholder (user). The user would still need an account with an off-site remoteStorage provider and elect to store and retrieve their data from there, rather than (or in addition to) the website operator’s S3/R2 buckets. The fact that the browser-based app is actually storing the data with the user’s remoteStorage provider is not meant to be transparent to the user.
Aha, so this request is specifically about R2, not S3.
S3 does not support per-user auth at all, so it cannot be used as an alternative back-end (with reasonable UX). R2 seems to support it in some way. (I haven’t looked into it more than glancing over the linked page.)
No, this is generally about any S3-compatible API (including Cloudflare’s R2 subset), and only the object- and bucket-level operations, with auth not being a factor—the auth story is the same for any other remoteStorage account.
NB: I have edited post 3 to be slightly clearer. Both the application creator and the user would be aware of and involved with the attempt to store the user’s data with the user’s remoteStorage provider; all reads and writes would be occurring after the point where the user has authenticated with the application and authorized remoteStorage.js (or whatever) to store data with his or her provider.
Sorry, I still don’t understand how this is supposed to work, and if it did, how it would be easier than just using a remoteStorage server in the first place. When using one in front of S3, its job is almost entirely that of handling the per-user auth and path permissions anyway.
If the developer is going to use rs.js in an app, then it would already be much easier to just replace whatever S3 functions it’s using with e.g. rsClient.storeFile().
There is also no way to get folder listings from S3 in unauthenticated requests, so folder-based sync would simply be impossible with nothing but pre-signed upload URLs/requests.
Perhaps you could link existing code for an S3-based app that works the way you describe, and point to exactly where it would be useful to have rs.js support introduced? Otherwise, this seems to be a purely theoretical discussion about what is actually practical software development.
If they don’t want to add remoteStorage, then why would they add remoteStorage.js, if the app has already been written and is functioning as intended? What is the benefit?
It would really help if you could just link to some code that exists, and where you think your idea would provide benefits to either the developers or the users, or both.
Any app following this model* should be able to use remoteStorage with minimally invasive changes on the app owner’s part.
* or a similar one (e.g. Cloudflare Workers are mentioned, but not a prerequisite—any means of obtaining an S3-style presigned URL relayed to the client would do)
This model is usually only used for user-uploaded media attachments, but not most actual user data, as explained in the first sentence of your screenshot. I don’t know a single app that uses pre-signed object storage URLs for any other user data, because it’s not possible to access that on the client side without any kind of metadata kept on and delivered from the server-side back-end of the application. Hence my confusion and requests for example code.
It seems to me like this is being proposed on a purely theoretical basis, without being aware of how applications are using this model in practice. That’s not something I’d want to discourage per se, but if there’s not even a single example of an app where this proposal would be possible and useful, then how would any core contributor be able to implement and test it?